{kind=link}
数日前、イーロン・マスク率いる xAI が最新大規模モデル「Grok 4」を正式に発表し、世界最強のAIであると豪語した。本稿では、中国語圏の解説記事をもとに、この新モデルの構造・性能・背景を分かりやすく整理し、日本語のニュース記事風にまとめた。記事のポイントは以下のとおりだ。
核心技術はマルチエージェント内在化 – 学習過程で複数エージェントの協調とリアルタイム検索を取り込み、モデル内部に討論や自己検証能力を組み込んだ。
思考チェーンや多モーダルに続く新たな潮流 – OpenAIの o1 は「思考チェーン内在化」、Google Geminiは「多モーダル内在化」を達成した。Grok 4 は「マルチエージェント内在化」の先駆けとして、基盤モデルの性能上限を一段と押し上げ、エージェント競争の時代をもたらす。
計算需要の急増 – 事前学習、後続学習、評価の各段階でスケーリング則が働き、推論時の計算消費が急増している。次世代の大規模モデル競争は算力調達の競争でもある。
ベンチマーク評価への疑念 – 各種指標で高いスコアを記録した一方、学習データへの流入で従来のベンチマークは汚染されている。実際のコーディング能力は弱く、xAIは専用のコーディングモデルを別途投入するとしている。
1 圧倒的な投入でベンチマークを席巻
xAIは自社のColossusスーパーコンピュータを用いてGrok 4を訓練した。計算資源の投入規模は前世代のGrok 3の10倍、Grok 2の100倍に達し、推論性能、多モーダル処理能力、長文の取り扱い能力が飛躍的に向上した。モデルには2つの料金体系がある。標準版「Grok 4」(月額30ドル)は単一エージェント版で、上位版「Grok 4 Heavy」(月額300ドル)は複数エージェントを同時に起動し、結果を統合できる。
一、コアバージョン比較
(コアバージョン比較)
| 比較次元 | Grok 4 | Grok 4 Heavy |
|---|---|---|
| アーキテクチャ設計 | シングル AI エージェント版で、純粋な推論モードに対応①。 | マルチ AI エージェント版で、4 つのスマートエージェントが並列動作し、協調して最適な回答を統合②①。 |
| コンテキストウィンドウ | 256k トークンをサポート①。 | Grok 4 と同様、256k トークンをサポート①。 |
| 価格設定 | 月額サブスクリプション料金 30 ドル、API 呼び出しは百万トークンあたり入力/出力がそれぞれ 3/15 ドル③④。 | 月額サブスクリプション料金 300 ドル、API 呼び出し価格は Grok 4 と同じ③①。 |
| パフォーマンス | HLE テストで得点 38.6 点③、HMMT テストで 90 点⑤。 | HLE テストで 44.4 点(業界最高)、HMMT テストで 97 点⑤③。 |
| ツール呼び出し能力 | リアルタイムWeb検索と基本的なツール呼び出しをサポート④。 | トレーニング段階で既にネイティブにマルチスマートエージェントの協調を生成し、ツール呼び出し効率がより高い⑤⑥。 |
実測データによれば、Grok 4はGPQA、AIME25、LCB(1~5月)、HMMT25、USAMO25など多くのベンチマークで、OpenAI o3、Gemini 2.5 Pro、Claude 4 Opusなどを上回った。
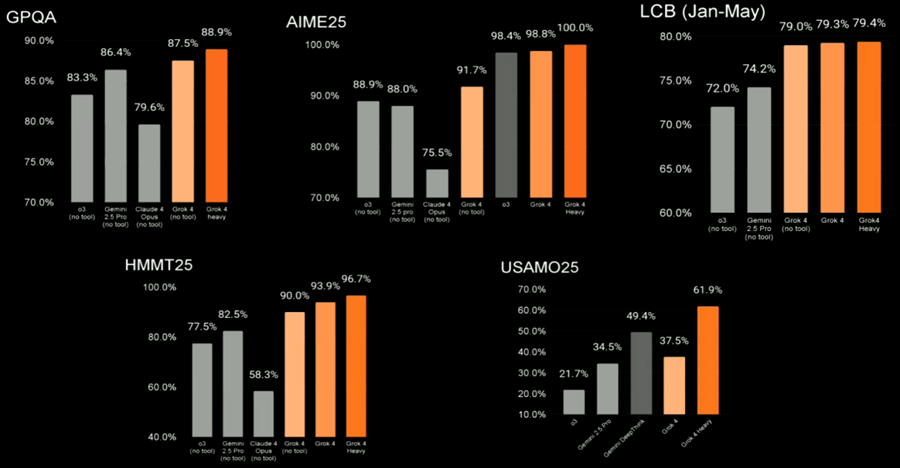
特に注目すべきは「AI界の最後の審判」と呼ばれる HLE(Humanity’s Last Exam) だ。Grok 4 Heavyは44.4 %の正答率を記録し、従来首位だったGemini 2.5 Pro(26.9 %)に大差をつけた。
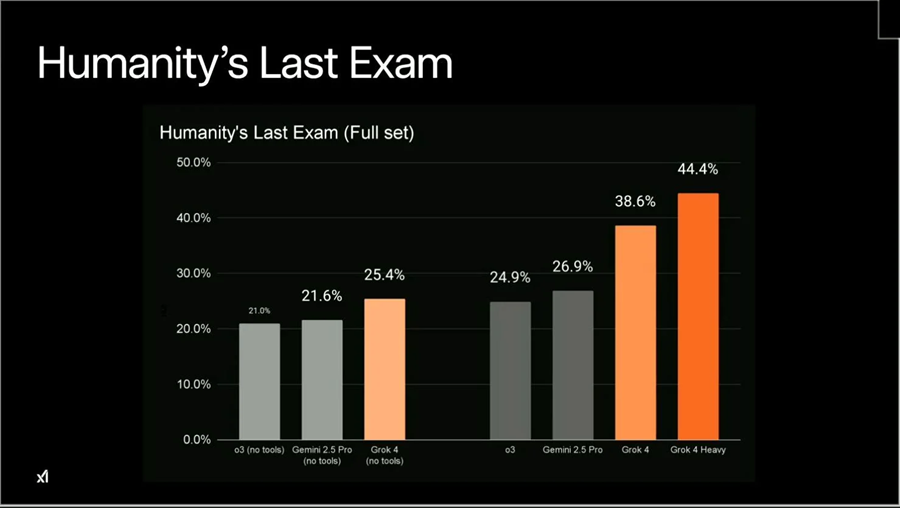
2 HLE:人類最後の試験
急速に向上する大規模モデルの性能に対し、既存のベンチマークでは知能レベルの差を測りきれなくなっている。そこで Center for AI Safety と Scale AI は2025年初め、「人類最後の試験(HLE)」を提案した。この試験は数学、人文学、自然科学など100以上の分野をカバーする2500問の難問から構成されており、インターネット検索では容易に答えが得られないよう設計されている。
これまで最強とされたモデルでもHLEの成績は芳しくなかった。例えばGPR‑4oの正答率はわずか2.7 %にすぎない。モデルは誤答を出す際に自信満々で回答することが多く、複雑な問題への脆弱性が浮き彫りになった。
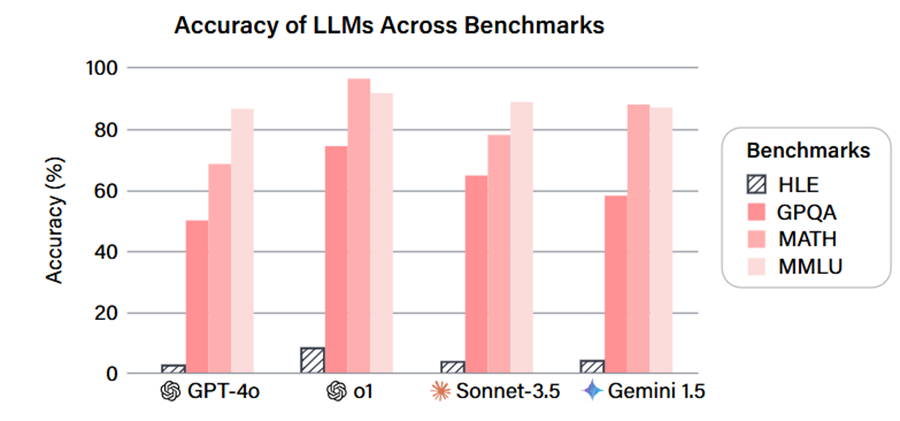
3 Grok 4の核心的な革新:マルチエージェント内在化
Grok 4 Heavyの最大の特徴は、学習段階から複数エージェントの協調を取り入れる点である。この「マルチエージェント内在化」によって、エージェント間の討論や自己検証がモデル自身の能力として備わる。背景には大規模モデルの進化の歴史がある。
思考チェーン内在化:2022年に流行した「CoT(Chain of Thought)」は、プロンプトを工夫してモデルに段階的思考を促すテクニックだった。2024年9月、OpenAIの「o1」は深い思考能力をモデル自体に組み込み、学習工程から推論工程までのスケーリング・トレーニングの新しいパラダイムを示した。
多モーダル内在化:Google Geminiはテキストと画像だけでなく、音声や動画も原生的に理解する「オムニモデル」の方向性を打ち出した。入力を文字列に変換してから処理する従来手法とは異なり、マルチモーダルを直接解釈することを目指している。
マルチエージェント化への発展:AIエージェント研究は単一タスクの自動化から、複数エージェントの協働による課題解決へと進んでいる。Grok 4はこの潮流を先取りし、動的なタスク分担や持続的な記憶など、Agentic AIの特徴をモデル内部に組み込んだ。

4 深い思考・エージェント・多モーダルの内在化
OpenAI o1が登場するまで、深い思考を引き出すには「Let’s think step by step」のようなプロンプト工学が必須だった。現在ではこれらのテクニックを学習過程に取り込み、モデルが自ら思考を展開するようになっている。同様に、Manusなどのエージェントツールで複雑なタスクを処理していた時代から、エージェント能力そのものがモデルに内在化されつつあり、競争はますます激しくなる。
さらに大きな潮流が 多モーダル内在化 だ。将来のモデルはテキストや画像に限らず、動画や音声もそのまま入出力できるべきだと考えられている。重要なのは、単に音声をテキストに変換して処理するのではなく、データの形式そのものを理解することである。Google GeminiはYouTubeの膨大な動画データを武器に、動画モーダルの入出力を実現しつつあり、OpenAIモデルにはまだない優位性を示している。
このようにAI能力の内在化が進む中、AIアプリケーション企業の競争優位は二つに集約される。第一に、長期にわたる独自データの蓄積。第二に、具体的な応用シーンに対する深い洞察だ。モデル自体が高度化しても、実世界の課題を理解し、適切に適用する能力が鍵となる。
5 AIコーディング能力への誤解とBase44の示唆
Grok 4の公開後、世界中のユーザーがこぞって試用し、xAIが公表したスコアと実感の間にギャップがあることが指摘された。最大の要因は、ベンチマーク問題集がインターネットを通じて学習データに流入し、評価が汚染されていることである。
実際のところ、Grok 4のコード生成能力はまだ発展途上だ。生成されたプログラムから主要ライブラリが抜け落ちたり、UIが粗雑だったりすることが多い。例えばゲームを作成する際、重要な pygame ライブラリがコードから漏れてしまうケースも報告されている。この問題を認識したイーロン・マスクは、今後数か月以内にコーディング特化モデルを公開すると予告した。

コーディングモデルについては誤解もある。優れたモデルとはLeetCodeの難問を解き、アルゴリズム競技に強い「オリンピック選手」のような存在だと思われがちだ。しかしビジネスの現場では、様々なGitHub リポジトリを統合し、データベースや認証機構、分析機能などを含む実際のアプリケーションを組み上げられる「実戦派」が求められる。
その好例が、2024年12月にイスラエルのプログラマー Shlomo が創業した Base44 だ。同社は自然言語のやりとりで一気通貫のソフトウェアを構築する「Vibe Coding」に特化し、わずか半年で8000万ドル(約57億円)でWixに買収された。ターゲットユーザーはプログラミング経験のない一般開発者であり、誰もが一からプロジェクトを構築できることが支持を集めた。Grok 4がより多くの実用的エージェント能力を内在化することで、将来はフルスタック開発者並みの力を発揮できると期待される。
6 Grok 4以降の世界の計算需要の展望
2025年に入ってから、海外の大規模モデル開発はまさに「四人舞台」の様相を呈している。xAI、OpenAI、Google DeepMind、Anthropicなどが代わる代わる新モデルを披露し、その背景には途方もない算力投資がある。報道によれば、xAIは毎月10億ドルを消費し、2025年の年間支出は130億ドルに達すると予測される。
Grok 4の訓練はテネシー州メンフィスにある自社のColossusスーパーコンピュータで行われた。20万枚のGPUを擁するこの施設への投資規模はGrok 2の100倍、Grok 3の10倍で、コンテキストウィンドウは25.6万トークンに拡大し、Claude 3 Opusを大きく上回る。推論の訓練にはColossusの計算能力の80 %が投入され、これがHLEで44.4 %という高得点を達成した直接の要因となった。
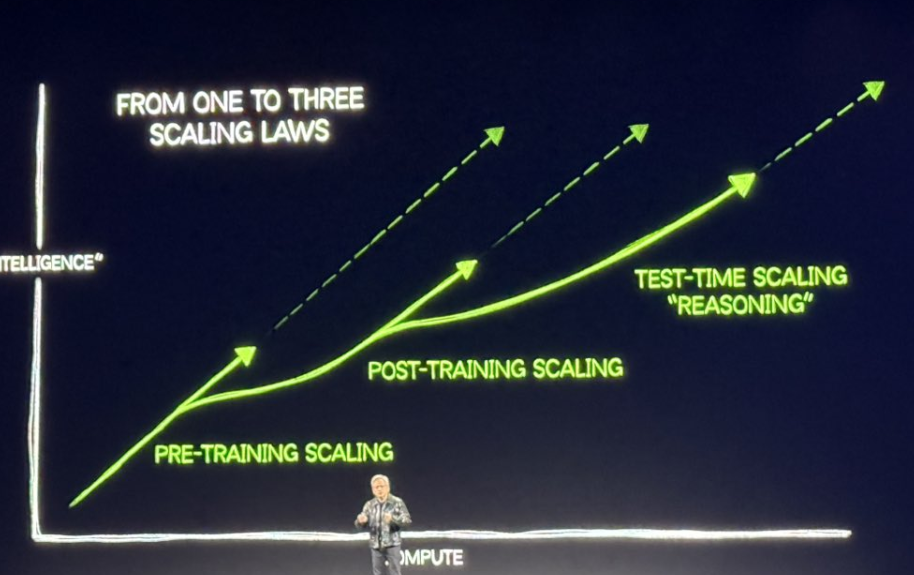
さらに、スケーリング則 は事前学習だけでなく後続学習やテスト時の推論にも適用される。ここ数年は主に事前学習への投資が注目されてきたが、今年に入り後続学習とテスト推論の計算需要が急増している。マルチエージェント内在化は算力需要の新たな軸を開き、今後も指数関数的な成長を続ける見通しだ。NVIDIAの黄仁勋氏が提唱した「スケーリング則三重奏」が実証されつつある。
7 結語:エージェント内在化の潮流と新たな軍拡競争
Grok 4が「エージェント能力内在化」の号砲を鳴らしたことで、他のAI大手も追随するとみられる。トレーニング面にはまだ大きなスケーリングの余地があり、次世代の大規模モデル訓練は軍拡競争の様相を呈するだろう。モデルの内部能力が進化する一方で、私たちが本当に活用すべきは独自データの蓄積と応用シーンへの深い理解である。
次世代AIが開く世界を、ぜひとも注視し続けたい。